- Published on
はじめに
LLMの出力をより賢くするためにはコンテキストを適切に管理する必要があるらしい。コンテキストに対する解像度を上げて、より賢いAIを作り出したい。コンテキストとはなにか、どのように整理すべきかを調べていく。
まずはこれを読んだほうがいいっぽい
https://github.com/humanlayer/12-factor-agents
What are the principles we can use to build LLM-powered software that is actually good enough to put in the hands of production customers?
上から順番に読んでいきポイントをまとめていく。
brief-history-of-software.md
https://github.com/humanlayer/12-factor-agents/blob/main/content/brief-history-of-software.md
ポイント
LLM を“黒箱の魔法”ではなく“ツール化されたコンポーネント”として扱うこと
LLM に任せる役割を 明確に限定する
例:自然文 → JSON の変換だけ、要約だけ、判定だけ
外部API操作や複雑なロジックを LLM 本体に背負わせない
LLM の出力は 構造化した形式(JSONなど) にする
プロンプト、コンテキスト、状態、制御フローを“明示的に”管理すること
- LLM の振る舞いを「なんとなく動く」にせず、どの情報を与え、どの順番で動かし、どんな状態で処理を進めるかをすべて設計側が明確に管理するということ。
LLMが扱う“状態”を外部に持たせ、ステートレスに制御する
- ステートをLLMにもたせると不安定になりうる
LLMの判断が危険なケースでは、“人間への問い合わせ(中断・確認)”を仕組みとして組み込むこと
構造化されたツール呼び出し用のJSON生成はLLMでツール実行はアプリ側で。LLM側でやると意図しないツール呼び出しが発生しうる。
- LLM の生成範囲を “意思決定” のみに限定し、実行は deterministic に保つ。以下のようなこの分離が重要という主張。
LLM:
- 「何を実行すべきか」の判断
- 「どのツールを使うべきか」の決定
- 「必要なパラメータを JSON で埋める」
アプリケーション:
- ツール実行
- エラー処理
- ログ
- リトライ
- セキュリティ
- ステート管理
小さく明確な責務のエージェントを分割して使うこと
factor-01-natural-language-to-tool-calls.md
ポイント
自然言語をそのままLLMの入力として扱うのではなく、構造化して扱うべき。たとえば自然言語を入力して自然言語を出力するケースだとしても以下のように扱うことが検討できる。
入力:「今期の目標を提案してほしい」
入力を構造化: { "intent": "generate_goal_suggestion", "domain": "business_performance", "constraints": null }
構造化した入力を取り込んだプロンプトを作る: あなたは目標設定アシスタントです。 以下の条件に基づいて、1つの目標案を自然言語で生成してください。 [条件] ・カテゴリ: business_performance ・形式: 「◯◯を達成する」のような文
必要なら出力も構造化する: { "goal_text": "営業利益100%を達成する", "category": "business_performance" }
出力:「営業利益100%達成する」
この例は極端からもしれないが、自然言語を構造化せずに取り込むより、構造を明確にした上でプロンプトを構築するなり、後続の処理の実行を決定するなりしたほうが、より管理しやすい。
例では入出力どちらも自然言語だが、自然言語を入力して実行コマンドを決定するケースにおいても構造化は有効な手段になりうる。必要な構造を定義して、管理化におくことを意識しよう。
factor-02-own-your-prompts.md
https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-02-own-your-prompts.md
ポイント
- プロンプトは 「コード/設定と同じ扱い」 をする — 単なる “その場限り” の文字列ではない
- バージョン管理 (Git など) に含める
- テンプレート + 変数で設計し、再利用可能にする
- テスト (入力例 → 期待出力) を書けるようにする
- ドキュメンテーションを整備する
- “Prompts を所有する” という視点を加えることで、「再現性・保守性・安全性」 をさらに高める方向に拡張できる。
factor-03-own-your-context-window.md
ポイント
- LLM に渡す “コンテキストウィンドウ”(会話履歴、外部データ、状態、過去のツール結果などを含む入力全体)は、 無計画に「全部/長く」入れればいい のではなく、開発者が「何を、いつ、どのくらい」入れるかを明示的に制御すべきである、という考え。
- 「コンテキストは記憶 (memory) であり、またワーキングメモリ (short-term memory)」である。限られたサイズ(トークン数)のリソースなので、 適切に整理・圧縮・選別 する必要がある。
- 適切な戦略として、たとえば次のような方法が挙げられている:
- 会話の歴史やドキュメントをそのまま全放りではなく、重要な内容だけを要約した形で保持する (要約 ⇢ 圧縮)
- “直近のやり取り + 全体の大枠 + 必須データ” といった優先順位をつけた情報選別を行う。不要情報 (過去の雑談、明らかに関係ないログ等) は捨てる。
- 必要であれば検索 (外部知識ベース、データベース、RAG など) から取得した情報だけを都度コンテキストに “動的に” 加える (動的コンテキスト補充) ことで、 効率よく・正確に必要情報を渡す。
- チャットログも必ずしも標準的なもの(単にラリー記録の配列)を使う必要はなく、独自に要約したり構造化したデータにしてもよい。
factor-04-tools-are-structured-outputs.md
ポイント
- LLMは構造化データを出力する
- LLMは実行モジュールを選択するだけで、実行方法をきめるわけじゃない
factor-05-unify-execution-state.md
https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-05-unify-execution-state.md
ポイント
- “実行状態 (Agent内部のワークフロー状況)” と “ビジネス状態 (アプリケーションの理論上の状態/DB等)” を分離せず、一貫した単一の状態管理 とすべき。
- 全ての操作をログ (イベントストリーム) に残し、永続化。これが ソース・オブ・トゥルース になる。
- こうすることで、エラー・中断・再開・監査などに強い、実用的で信頼性の高いエージェントが構築できる。
factor-06-launch-pause-resume.md
https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-06-launch-pause-resume.md
ポイント
Agent は、単なる無限ループや “LLM が勝手に次ツールを呼び出し続ける” ブラックボックスではなく、外部からライフサイクルをコントロールできる構造にする。具体的には、たとえば HTTP API、関数呼び出し、ジョブキュー、スケジューラ等を通じて、以下のような操作が可能にする:
start()— 新しいタスク/セッションを開始pause()— 現在の実行を一時停止 (たとえば human-in-the-loop を待つ、または外部イベントを待つ)resume()— 停止状態から再開。どこで止まっていたか (checkpoint/状態) をもとに続きから実行を再開- この設計により、Agent を同期処理ではなく非同期/分散で使いやすくなる。たとえば、ジョブキューや外部イベント、手動レビュー、別プロセスからの起動など、柔軟な運用が可能になる。
コンテキストとは
LLMにインプットするあらゆる情報のこと。それはユーザ入力かもしれないし、RAG的な情報取得の結果かもしれないし、チャット履歴みたいなセッションデータかもしれない。
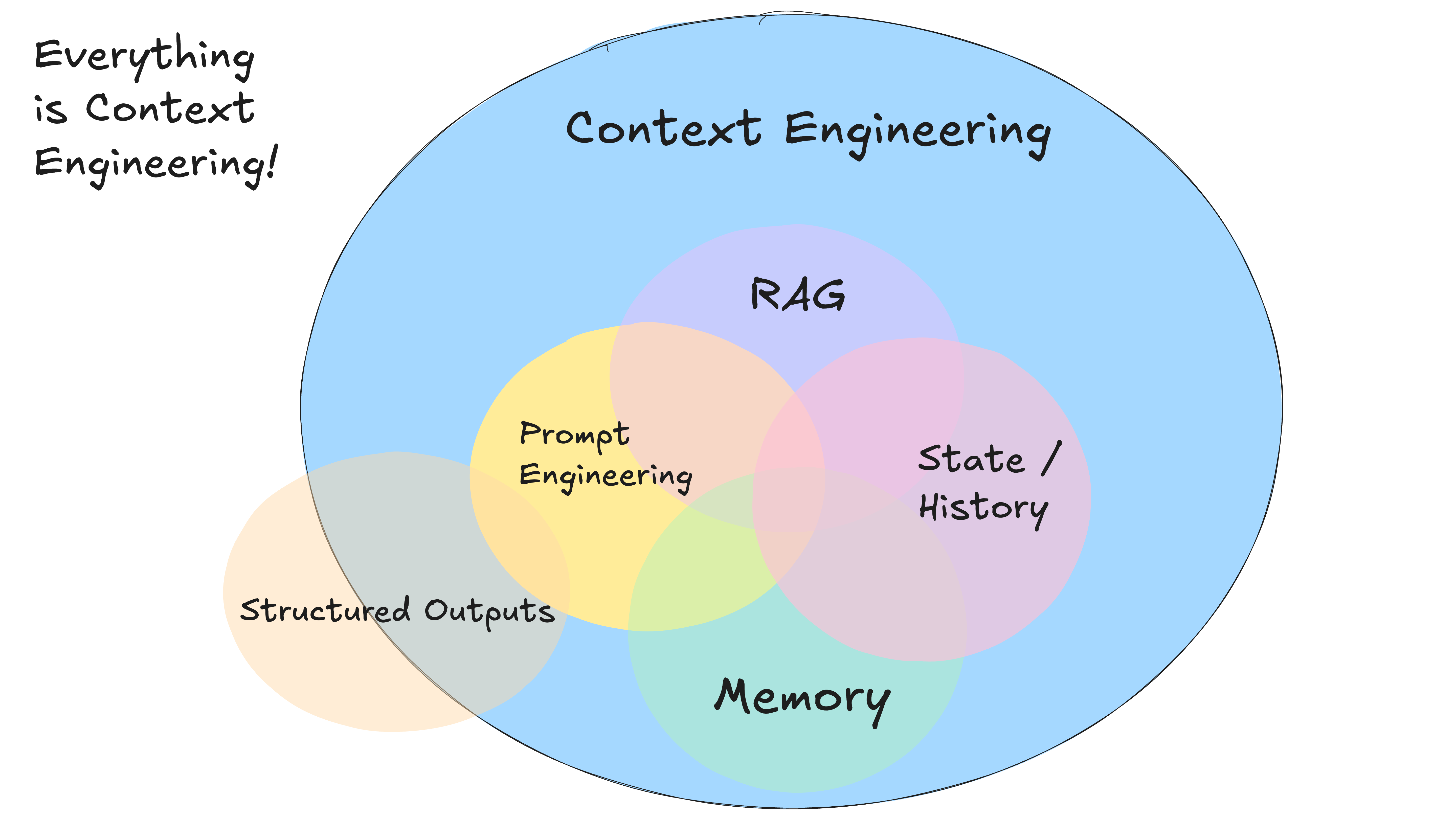
コンテキストエンジニアリング
LLMから適切な出力を引き出すには、質の高いコンテキストを入力する必要がある。この質の高さは定量的に測定が難しいかもしれないが、単に持っているデータの全量を渡したり、あるいは情報を渡さなすぎたりすると求める回答が得られないだろう。
理想的な回答を引き出すためにコンテキストをどのように管理し、取得し、LLMに与えるか考え、設計することをコンテキストエンジニアリングと呼ぶ。
https://x.com/lenadroid/status/1943685060785524824

おわりに
コンテキストとは、LLMに入力するあらゆるデータのことであると理解した。また、コンテキストをどのように管理し取り扱うか考えることをコンテキストエンジニアリングと呼ぶ。コンテキストエンジニアリングの具体的な手法に関する深堀は後続の記事で取り扱うことにする。まずは
参考
https://zenn.dev/karaage0703/articles/76f2a1b20cd6c1
https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html